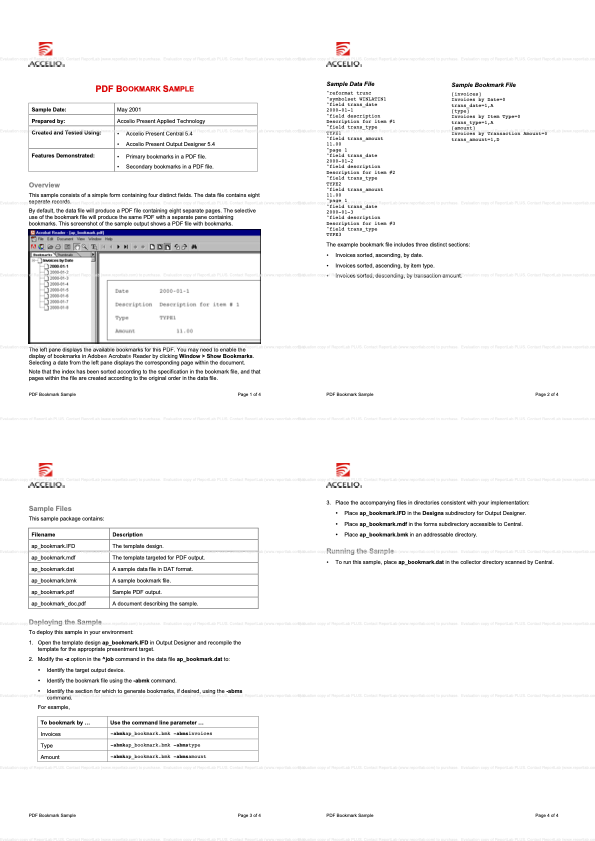
PageCatcher - working with existing PDF files
ReportLab’s open source and commercial products focus on generating PDF files, but sometimes you want to work with ones that already exist. Some use cases include:
- Placing your content into or over a professionally designed background or cover sheet.
- Importing static documents such as terms and conditions.
- Re-using company logos, letterheads, vector art or graphics.
If you are authoring your documents in Report Markup Language, the machinery is seamless and hidden under tags such as includePdfPages, catchForms and doForm. These are documented below as well as in our specification.
However, if you have already written a substantial solution using our Open Source code, laying out documents in Python code, you may need access to these functions, which are in the rlextra/pageCatcher subpackage.
Under the hood, the PDF specification contains “Form XObjects”, reusable forms which can be referenced by your pages. The api calls below let you import and use these.
We also have a command line utility which lets you test if a PDF file is compatible, and quickly combine, merge and extract pages. And we offer a higher level Python class, PdfExplorer, which is useful for finding text in pages and copying across content to new documents.
Include Pages (RML)
When using RML, we noticed that many customers wanted the ability to include other pages in their PDF's. Inside the rml.dtd or the tag definitions you can find includepdfpages.
<includePdfPages fileName, pages, dx, dy, sx, sy,
orientation, isdata,leadingBreak,
template, outlineText, outlineLevel,
outlineClosed, pdfBoxType, autoCrop,
CropBox, pageSize, alone
callback, user_data/>
Arguments meaning
fileName string name of a .pdf or .data file or an object with a read method
pages If None all pages will be used, else this argument can
be a string like '1,2,4-6,12-10,15' or an explicit
list of integers eg [1,2,7].
dx,dy, translation together all these make up a transformation
sx,sy, scaling matrix
degrees, rotation
orientation None or integer degrees eg 0 90 270 or 'portrait'/'landscape'
isdata True if fileName argument refers to a .data file (as
produced by pageCatcher)
leadingBreak True/False or 'notattop' specifies whether a leading
page break should be used; 'notattop' means a page break
will not be used if the story is at the top of a frame.
template If specified the index or name of a template to be used.
outlineText Any outline text to be used (default None)
outlineLevel The level of any outline text.
outlineClosed True/False if the outline should be closed or open.
pdfBoxType which box to use or None or [x0,y0, x1,y1]
autoCrop True/False crop/don't crop with CropBox (default is False)
boxname use for cropping
[x0,y0, x1,y1] crop area
pageSize default None ie leave page size alone
'set' adjust page size to incoming box
'fit' scale incoming box to fit page size
'orthfit' orthogonally scale incoming box to fit
'center' or 'centre' center the incoming box in
the existing page size
[x0,y0, x1,y1] use this as the page size
callback draw time callback with signature
callback(canvas,key,obj,pdf_data,user_data)
canvas the canvas being drawn on
key may be 'raw-pre'|'transformed-pre'|'transformed-post'|'raw-post'
obj the flowable calling the callback
pdf_data ('fileName',pageNumber)
user_data user data passed down to the flowable from
IncludePdfFlowable.
user_data information to be passed to the callback
e.g.
Example rml file:
<!DOCTYPE document SYSTEM "rml.dtd">
<document filename="test_include.pdf">
<template>
<pageTemplate id="main">
<frame id="first" x1="72" y1="72" width="451" height="698"/>
</pageTemplate>
</template>
<stylesheet>
<!-- This is your stylesheet -->
</stylesheet>
<!-- The story (your actual content) starts below this comment -->
<story>
<includePdfPages filename="test.pdf"/>
</story>
</document>
rml2pdf test_include.rml
Forms
The PDF specification formX objects which are reusable elements of a document e.g. a reusable footer. The concept of forms is at the heart of PageCatcher. We capture the pages from a PDF file and place them in storagefile for later use or in memory as formX objects.
Make Forms
On the command line:
PageCatcher makeforms [PDF] [-s storagefile] [-p prefix] [-f form name]
[--password password] [--test PDF test file]
[--all] [pagenumber]*
Parameters
----------
PDF : string
filename of PDF file to extract data from
s : string, optional
storage file, filepath to store extracted data
p : string, optional
prefix, saved forms will be saved using prefix followed by pagenumber.
e.g. prefix0.data. N.B. page numbers go from 0 to length of document -1.
f : string, optional
If the formname option is used then the first form only will be called formname.
password : string, optional
The password when provided should be the "read" (USER) encryption password
or the pdffile.
Only provide the password option when the pdffile has be
encrypted using the PDF 3.0 Standard Encryption method.
test : bool, optional
Calling test reconstructs the extracted data and
then the captured pages are reimported and placed in the test file,
overlayed with a centimeter grid.
This can be useful when determining where objects should be located in (x,y).
all : bool, optional
Capture all the pages. Default is All.
pagenumber : List(int), optional
A space seperated list of the page numbers you wish to extract.
e.g. % pageCatcher makeforms picture.pdf -s pic.data -p pict --test pictest.pdf 0 2 extacts the first and third page.
e.g.
pageCatcher makeforms picture.pdf -s pic.data -p pict --test pictest.pdf 0 2
The output test file with overlayed centimetre grid looks like the following:

Really useful for editing locations of images or text blocks in PDF's.
Using the python API from rlextra.pageCatcher import pageCatcher we can also store those forms:
# pageCatcher.storeForms
def storeForms(frompdffile, storagefile, pagenumbers=None, prefix="PageForms", all=None,
fformname=None, password=""):
Parameters
----------
frompdffile : string
filename of PDF file to extract data from
storagefile : string, optional
storage file, filepath to store extracted data
pagenumbers : List(int), optional
A space seperated list of the page numbers you wish to extract.
e.g. % pageCatcher makeforms picture.pdf -s pic.data -p pict --test pictest.pdf 0 2 extacts the first and third page.
prefix : string, optional
prefix, saved forms will be saved using prefix followed by pagenumber.
e.g. prefix0.data. N.B. page numbers go from 0 to length of document -1.
all : bool, optional
Capture all the pages. Default is All.
formname : string, optional
If the formname option is used then the first form only will be called formname.
password : string, optional
The password when provided should be the "read" (USER) encryption password
or the pdffile.
Only provide the password option when the pdffile has be
encrypted using the PDF 3.0 Standard Encryption method.
Returns
-------
names : List(str)
Returns names of forms stored.
e.g. (For a three page PDF)
from rlextra.pageCatcher import pageCatcher
pageCatcher.storeForms(
frompdffile="picture.pdf",
storagefile="pic.data",
prefix="pict",
pagenumbers=[0, 2]
)
Restore Forms (API)
The forms would be little to no use if we couldn't restore them later.
To do this we can use the python api restoreForms:
# pageCatcher.restoreForms
def restoreForms(storagefilename, canv, formnames=None,
allowDuplicates=0):
Parameters
----------
storagefilename : string
File location of storage data e.g. "storage.data"
canv : ReportLab Canvas object
Canvas to write in stored PDF data.
formnames : List(str) or str
A list containing the forms (pages) you wish to reconstruct. Either a list of strings or the string name itself.
allowDuplicates : int
Should you want to allow duplicate forms (0 or 1). 1 is True.
Returns
-------
formnames : List(str)
Returns names of forms restored.
e.g.
import pageCatcher
import reportlab
canvas = reportlab.pdfgen.Canvas(...)
storagefilename = "pic.data"
formnames = pageCatcher.restoreForms(storageFileName, canvas)
canvas.doForm(formnames[0]) # use the first form (as a backdrop for a page, for example).
canvas.save()
Restore Forms (RML)
Catching Forms in RML: If you have production versions of both RML2PDF and PageCatcher you can use a special Report Markup Language tag catchForms which imports all forms from a PageCatcher storage file for use in an RML document.
For example: The following RML code fragment draws a caught form PF0 (stored in storage file storage.data) onto a page backdrop.
<pageDrawing>
<catchForms storageFile="storage.data"/>
<doForm name="PF0"/>
</pageDrawing>
The catchForms tag can occur anywhere where a doForm tag can occur.
4Page
Four page or 4Page is useful for paper saving (amongst other things), it's fairly simple. It takes in a PDF and spits out the same PDF but placing 4 pages into one.
As an example we can use this sample PDF from adobe.
PageCatcher makeforms [PDF]
Parameters
----------
PDF : string
filename of PDF to extract data from
e.g.
pagecatcher 4page c4611_sample_explain.pdf
Output:
Count
Count is another simple command, much like 4page. Simply count how many pages are in a PDF without opening it!
PageCatcher count --pdf [filepath]
Parameters
----------
pdf : string
filename of PDF to extract data from
e.g.
pagecatcher count --pdf c4611_sample_explain.pdf
Output:
4
Pages
Much like count but returns the names of each page.
PageCatcher count --pdf [filepath]
Parameters
----------
pdf : string
filename of PDF to extract data from
e.g.
pagecatcher pages --pdf c4611_sample_explain.pdf
Output:
PageForms0 PageForms1 PageForms2 PageForms3
Note
Not functional right now...
Exec
Not functional right now...
CombinePDF
Using the python API much like Include pages, we wanted a way to append PDF's to each other.
# from rlextra.pageCatcher.pageCatcher import CombinePdfs
def combinePdfs(combinedFileName, list_of_pdf_filenames):
Parameters
----------
combinedFileName : string
Output filename.
list_of_pdf_filenames : List(string)
A list of filenames to read in and copy.
This route is also available in memory using combinePdfsInMemory.
Copy Pages
Much like CombinePDF we wanted to be able to copy in PDFs to a Canvas object.
# from rlextra.pageCatcher.pageCatcher import copyPages
def copyPages(frompdffile, tocanvas, withoutline=1):
Parameters
----------
frompdffile : string
Filename of PDF file to copy in.
tocanvas : Canvas Object
Canvas object you wish to copy page into
withoutline : int
Add in outline entries. 0 or 1.
This route is also available in memory using copyPagesInMemory.
e.g.
from rlextra.pageCatcher.pageCatcher import copyPages
from reportlab.pdfgen import canvas
from PIL import Image
import os.path
def doappend(topdffile, frompdffilelist):
canv = canvas.Canvas(topdffile)
for frompdffile in frompdffilelist:
filepath, extension = os.path.splitext(frompdffile)
if extension.lower() in [".png", ".jpeg"]:
print("converting image to pdf")
im = Image.open(frompdffile)
im = im.convert("RGB")
savepath = "%s.pdf" % filepath
im.save(savepath)
print("copying", savepath)
copyPages(savepath, canv)
elif extension.lower() == ".pdf":
print("copying", frompdffile)
copyPages(frompdffile, canv)
else:
raise Exception("Non supported filetype %s" % frompdffile)
print("\n\nnow writing", topdffile)
canv.save()
if __name__ == "__main__":
# edit this
combine_list = [
"pdf1.pdf",
"pdf2.pdf"
]
doappend("output.pdf", combine_list)
PDFExplorer
PDFExplorer can be used to extract content from PDF files.
# from rlextra.pageCatcher.pdfexplorer import PdfExplorer
class PdfExplorer(fileNameOrContent):
Parameters
----------
fileNameOrContent : string | bytes
Path to PDF or the content itself
Methods
-------
def getText(self, pageNo):
Extract text from a page.
Parameters
----------
pageNo : string
Page number to extract text.
def getForm(self, pageNo):
Get the form object for that page.
Parameters
----------
pageNo : string
Page number to extract text.
def getPageContent(self, pageNo):
Decompressed PDF, which includes text.
Parameters
----------
pageNo : string
Page number to extract text.
def pageMatchesRe(self, pageNo, regex, textOnly=0):
Return matched regex object if found.
Parameters
----------
pageNo : string
Page number to extract text.
regex : string
Regex to match.
textOnly : int
Only search using getText rather than getPageContent. 0 or 1.
def findTextMatching(self, pageNo, pattern, textOnly=0):
Find text matching string.
Parameters
----------
pageNo : string
Page number to extract text.
pattern : string
String to match.
textOnly : int
Only search using getText rather than getPageContent. 0 or 1.
def findPagesMatching(self, pattern, textOnly=0, showGroups=0):
Find matching pattern for all pages, return pages with matching pattern.
Parameters
----------
pattern : string
String to match.
textOnly : int
Only search using getText rather than getPageContent.
0 or 1.
showGroups : int
Show the matching groups in results.
e.g.
from rlextra.pageCatcher.pdfexplorer import PdfExplorer
from reportlab.pdfgen.canvas import Canvas
c = Canvas("testExtraction.pdf", pageCompression=0)
c.drawString(100, 700, "this is top level text")
c.save()
pdfData = c.getpdfdata()
exp = PdfExplorer(pdfData)
page1text = exp.getText(0)
print(page1text)
With the output being:
this is top level text
drawPdfImage
drawPdfImage can be used to quickly draw PDF's inside a canvas, like canvas.drawImage.
def drawPdfImage(fileName, canv, x=0, y=0, width=None, height=None,
preserveAspectRatio=False, pageNumber=0,
showBoundary=False,anchor='sw', boxType='MediaBox',
anchorAtXY=False):
Parameters
----------
filename : string
File name to PDF to add.
canv : Canvas Object
Canvas object to draw PDF on.
x : int
X coordinate in pixels.
y : int
Y coordintate in pixels.
width : int
Width in pixels.
height : int
Height in pixels.
preserveAspectRatio : bool
Preserve aspect ratio flag.
pageNumber : int
Desired page to add PDF to.
showBoundary : bool
Show boundary around PDF drawn.
anchor : string
Anchor position for aspect ratio.
See from reportlab.lib.boxstuff for more.
boxType : string
Type of box.
See from reportlab.lib.boxstuff for more.
anchorAtXY : bool
Flag for anchoring.
from reportlab.lib.boxstuff for more.
Known Deficiencies and Caveats
PageCatcher does not support PDF pages with stream content arrays compressed using the LZW compression method. (Unfortunately this is used in British tax forms). We are working to add this support.
PageCatcher cannot capture pages that contain "Active PDF Form" annotations (such as checkboxes or fill-in text areas).
You must supply a user password to process encrypted PDF files
pageCatcher... --password MYUSERPASSWORD
Since the preprocessor step for PageCatcher parses the entire PDF file, parsing very large files may consume a great amount of computational resources even if only one page is extracted from the file.
Workarounds
If you have a copy of Adobe's Distiller, you can use it to work around the majority of problems. To do this, use Distiller's printer emulation to "print to PDF" and the file created will be digestible by PageCatcher. (One known exception: where the PDF file is encrypted and printing is not permitted).
Old Documentation
If there was something you remember seeing on the old documenation but it is not here, don't worry we still have it here.
Feedback
We need and welcome feedback to help make this into a great product! Email info@reportlab.com, or join our group of 200+ existing users by emailing reportlab-users@reportlab.com. Enjoy!